Filesystem encoding and PHP
Many PHP applications save files to a local filesystem. Most of the times for the bulk of readers here you'll likely only ever store files using US-ASCII encoding, either because your filenames are simply based on databasefields (as you should try in most cases), or simply because most of your users never have a need for non-english characters.
When you do though, it's important to know how operating systems cope with these characters. Unsurprising, all of them do this differently.
To illustrate the differences, I'm going to do some tests on Ubuntu, OS/X 10.6.3 and Windows XP and 7.
Linux
In Linux filenames are binary. Linux does not care what encoding your filenames are, and it will accept anything besides 0x00. This means filenames can contain carriage-returns (\n), tabs (\t) or even a bell (ascii code 07).
To illustrate this, I'm going to make a tiny file using a php script:
<?php
file_put_contents("saved by the \x07.txt","contents");
?>
After running this I simply get a questionmark when viewing the file using 'ls', but when I auto-complete it, it expands to ^G (which is bell). In Nautilus, this is displayed:
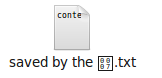
If I run this script:
<?php
print_r(glob('saved*'));
?>
The output is simply missing my bell character, and I get a short beep.
This doesn't mean it's a good idea to do this. Even though the underlying filesystem is binary-safe, applications that list filenames will still have to make a decision on an encoding to display the characters to the user. You can't even show this character in any PHP page, and firewalls might even block this if you used this in a url.
This also applies to the applications on your linux machine. Most of them, such as Gnome Terminal and Nautilus, default to UTF-8. However, I believe for the PuTTY application this was for the longest time ISO-8859-1 (latin1). A symptom of this is that any non-ascii characters look different when read them from Putty vs. Nautilus.
The other thing I wanted to test on linux is how it behaves if I create a file in the filemanager using a special character. For this example I'm using ü, because it's a bit ambiguous as there's multiple ways to encode it using unicode (more on this later) and it also appears in ISO-8859-1.
Back to the test. I'm now creating a new file from the Nautilus interface, and want to see how it shows up for PHP. Im creating a file called test_ü.txt and listing it with the following script:
<?php
list($file) = glob('test_*');
echo urlencode($file) . "\n";
?>
Output:
test_%C3%BC.txt
%C3%BC is the UTF-8 encoding of codepoint U+00FC, which is the most common way to encode ü. Great!
The last test is to create this file using ISO-8859-1/latin1 encoding. The latin1 representation of ü is 0xFC. The script for this:
<?php
file_put_contents("uumlaut_\xFC.txt","contents");
?>
Linux stores the file with that exact byte sequence. 'ls' shows the questionmark again, and this type in gnome I'm getting the typical 'incorrect encoding' question mark.
OS/X
On OS/X all filenames are encoded as UTF-16. You don't have to know about this, because the API's PHP uses are UTF-8, and are transparently translated for you.
We'll start with the bell test. The result is the same as on linux. The bell character is represented by ?. When checking it out in finder, the character is missing altogether. It's definitely still there though, as the following script illustrates:
<?php
list($filename) = glob('saved*');
echo urlencode($filename) . "\n";
?>
Output:
saved+by+the+%07.txt
Next, we're going to do the ü test. First, I'll encode it as latin-1, which would be invalid for this UTF-8 filesystem.
<?php
file_put_contents("uumlaut_\xFC.txt","contents");
?>
This one is weird. If I now do 'ls', the result is this:
drwxr-xr-x 10 evert2 staff 340 16 Apr 17:08 .
drwxr-xr-x 32 evert2 staff 1088 16 Apr 16:53 ..
-rw-r--r-- 1 evert2 staff 8 16 Apr 16:54 saved by the ?.txt
-rw-r--r-- 1 evert2 staff 121 16 Apr 16:54 test1.php
-rw-r--r-- 1 evert2 staff 8 16 Apr 16:54 test2.php
-rw-r--r-- 1 evert2 staff 101 16 Apr 17:07 test3.php
-rw-r--r-- 1 evert2 staff 57 16 Apr 17:08 test4.php
-rw-r--r-- 1 evert2 staff 8 16 Apr 17:08 uumlaut_%FC.txt
Instead of taking the literal bytes, OS/X urlencoded them, and stored those sequences instead. This translation is transparent; but it might be confusing if you ever try to store latin1 filenames from your users.
The last test is to store the umlaut again, but this time using the correct utf-8 sequence:
<?php
file_put_contents("uumlaut2_\xC3\xBC.txt","contents");
?>
Upon first sight this seems to have worked as expected, but it gets weird when we check out how this was actually stored:
<?php
list($file) = glob('uumlaut2_*');
echo urlencode($file) . "\n";
?>
Output:
uumlaut2_u%CC%88.txt
OS/X stored u0xCC88 instead of 0xC3BC. Note that the u is not a typo. OS/X uses a different way to store the ü. The encoding we used is unicode codepoint U+00FC, which is ü. OS/X first stores the u and the two little dots as separate characters, taking up 3 bytes instead of 2.
This is called normalization. Unicode defines a few different normalization models which dictate how these combinations of characters are stored. So even though they are different byte-sequences and different codepoints they are still considered equivalent.
The PHP intl extension includes a class that allows you to do the unicode normalization yourself, namely the normalizer class. The documentation also includes a short description of what the 4 different normalization forms are. OS/X uses a slightly modified version of Normalization Form D (yes, nobody can ever standardize on anything).
This is how you would do this conversion yourself:
<?php
$before = "\xC3\xBC";
$after = Normalizer::normalize($before, Normalizer::FORM_D);
echo 'Before: ', urlencode($before), "\n";
echo 'After: ', urlencode($after), "\n";
?>
Output:
Before: %C3%BC
After: u%CC%88
This normalization process for OS/X is also transparent. Whenever you will try to open a file with the wrong normalization form, OS/X will put it in form D before opening.
Windows
Windows also uses UTF-16 to store filenames (using NTFS). Just like OS/X, this translation is done automatically, due to the filesystem api's php uses. We'll start with the bell-test:
<?php
file_put_contents("saved by the \x07.txt","contents");
?>
Output:
Warning: file_put_contents(saved by the .txt): failed to open stream: Invalid argument in C:\Documents and Settings\Administrator\test\test.php on line 2
Indeed, windows does not allow control characters such as bell. The second thing we'll try is the latin-1 encoded ü:
<?php
file_put_contents("uumlaut_\xFC.txt","contents");
list($file) = glob('uumlaut_*');
echo urlencode($file) . "\n";
?>
Output:
uumlaut_%FC.txt
Not only did windows accept this encoding, it also displayed correctly in both cmd.exe, and the windows explorer. So it appears that windows and PHP actually translate from and to ISO-8859-1/latin1 instead of UTF-8. When trying this with the UTF-8 encoding of ü this gets confirmed.
<?php
file_put_contents("uumlaut2_\xC3\xBC.txt","contents");
list($file) = glob('uumlaut2_*');
echo urlencode($file) . "\n";
?>
Output:
uumlaut2_%C3%BC.txt
While windows stores this correctly, the filename is now garbled in cmd.exe and windows explorer. Here it looks like ü. This is pretty bad. I do know that Windows does support UTF-8, so I can't help but wonder what would happen if I do the exact opposite: making a file containing non-ascii characters in windows explorer, and reading out the filename in PHP.
The results were interesting. I used the ü again, and 한글, which is the name of the korean writing system, hangul. With 2 files in this directory, I simply did:
<?php
$files = glob('*');
foreach($files as $file) {
echo urlencode($file), "\n";
}
echo "total: " . count($files) . "\n";
?>
Output:
test.php
uumlaut%FC.txt
total: 2
My korean file was completely missing. Just to make sure I did the same with scandir:
<?php
$files = scandir('.');
foreach($files as $file) {
echo urlencode($file), "\n";
}
echo "total: " . count($files) . "\n";
?>
Output:
.
..
hangul_%3F%3F.txt
test.php
uumlaut%FC.txt
total: 5
Oddly enough it did show up here. This time however, the korean characters were replaced by %3F, which is, surprise: the question mark. We've seen characters replaced by question marks before, but this is the first time it ends up in a literal string.
Conclusion
Using non-latin characters in filenames is messy. It would be possible to provide a consistent experience, if it weren't for windows. Windows does have all the proper api's to deal with international filenames, but I can only assume PHP simply does not support them. I do believe this was scheduled for PHP6, but now that's off the hook. I hope the filesystem api's are replaced even before the entire language is unicode-based.
While the Linux solution (treat everything as binary, allow everything besides 0x00) might seem like the most straightforward, in the end filenames are meant to be written or read by people which means it will be encoded.
The best system in this case really is OS/X, which not only treats everything as UTF-8, it also handles incorrect sequences well and makes sure that characters with an identical meaning are also always stored the same way (normalization).
Here's what I recommend:
If you want to support all characters on all operating systems in a consistent matter, you have no other option than to use an intermediate encoding. You could for instance simply urlencode all your filenames before writing them to disk.
Url-encoding does not mean you can forget about the encoding though. urlencoding means that a different way is used to store certain bytes, but the characters they represent remain the same. Therefore, you should always make sure that the filenames you're using are valid UTF-8 sequences. UTF-8 is today's encoding of choice.
If you know absolutely sure you will only use characters in the ISO-8859-1/latin-1 character-set, the following table applies:
| Windows | Encode using ISO-8859-1 |
| Linux | Encode using UTF-8 (will accept other encodings, but not recommended). |
| OS/X | Encode using UTF-8. Will transparently encode to normalization-form D |
Here's a table of sequences and what happens on specific operating systems:
| url-encoded filename | description | Linux | OS/X | Windows |
|---|---|---|---|---|
| %07 | bell | %07 on disk | %07 on disk | throws error and doesn't save |
| %FC | ü in ISO-8859-1 | %FC on disk, question marks in UI's | %25FC on disk (%25 = %, so the literal string %FC on disk). | %FC on disk, correct in UI |
| %C3%BC | ü in UTF-8 normalization form C | %C3%BC on disk. correct in UI | u%CC%88 on disk, correct in UI | %C3%BC on disk, shows up as ü in UI's |
| u%CC%88 | ü in UTF-8 normalization form D | u%CC%88 on disk, correct in UI | u%CC%88 on disk, correct in UI | untested, but assumed to be similar to the last testcase. |
Configuration list
Lastly, the list of relevant software I used for this:
- Windows
- Tested on XP SP3 and 7
- PHP 5.3.2 VC9 x86 build from windows.php.net
- NTFS filesystem
- Linux
- Ubuntu 9.10
- PHP 5.2.10 from ubuntu package repository
- ext3 filesystem
- OS/X
- v10.6.3
- PHP 5.3.1 as shipped with OS/X
- HFS+ filesystem </li>
Comments
Erwin Moller •
Thank you for posting this.
I was pulling out my hairs with this issue on Win2008, and I cannot solve it.
I have filenames with accents, and PHP refuses to open them.
SInce storing the files as with different names isn't an option, I must keep on searching.
I am going to try my hand at comp.lang.php
Nicolas Grekas •
On Windows, you might try using COM objects:
https://gist.github.com/nic...
sdcd •
OKS
Kybrex •
Great and useful post! :) Thx.
Peter •
Using non-latin characters in filenames works with the php framework rexo (http://rexo.ch). I tested under windows, php 6.